

What really changed with Gen-AI compared to "classic" ML systems: a technical perspective
This white paper delves into the nuanced distinctions between Generative AI (Gen-AI) systems and traditional machine learning (ML) algorithms, emphasizing that Gen-AI brings its own set of unique challenges and an endless number of opportunities. It highlights the low barrier to entry for Gen-AI systems, allowing for rapid proof of concept development, yet underscores the complexity and effort required for scalable deployment due to the intricacies of system components and their interactions. Reliability emerges as a significant concern, particularly given the non-deterministic nature of LLM-based systems and their propensity for "hallucinating" or producing inaccurate outputs, necessitating innovative approaches to ensure system reliability. Interpretability, or understanding why an AI system makes certain decisions, is identified as a critical challenge, impacting trust and the ability to improve models. The post also touches on the complexity introduced by the myriad of parameters and hyperparameters in Gen-AI systems, from prompting strategies to agent learning techniques, highlighting the ongoing need for deep engineering work to normalize data and clarify semantics.
Starting by stating the obvious, Generative AI is not a replacement for classic ML algorithms, which still excel in accomplishing a number of tasks. There are many debates over their real (and emerging) capabilities and with no doubt their scope of applicability will continue to increase. Due to their broad and unprecedented pace of adoption and applicability to a plethora of use cases, numerous debates have emerged regarding Large Language Models (LLMs), specifically concerning their intelligence, ability to understand, reason, and plan. Although philosophically interesting, as discussed in ['Does AI match human intelligence?' — which is just the WRONG question to ask], the real question is whether such models are useful, which seems to be indisputable.
Are Gen-AI systems so different than "classic" ML ?
Without a doubt.
At the heart of Gen-AI systems, such as LLMs, are transformers (https://en.wikipedia.org/wiki/Transformer_(deep_learning_architecture), which are essentially deep neural networks equipped with attention mechanisms. Moreover, prompting is essentially a method to 'feed' the system, enabling dynamic access to a knowledge/vector database through the use of various embeddings—nothing truly revolutionary.
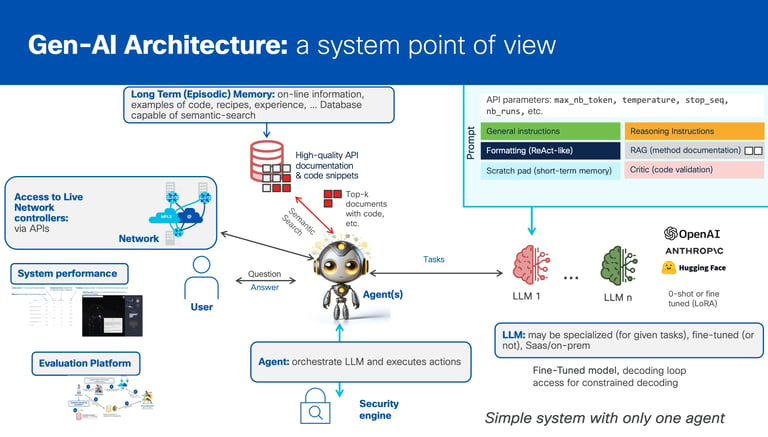
As illustrated in the figure, such systems are composed of a myriad of intricately intertwined components, each with its own (and hard to predict) influence on the overall behavior and efficacy of the system. This complexity is further compounded by their capability to access real-time information from production systems via the use of Open APIs. This 'ecosystem' is then augmented with numerous components responsible for alignment, hallucination mitigation, security, and fairness, to name a few. Moreover, the highly promising architecture of multi-agents will allow for the live collaboration of multiple agents with true self-improving capabilities, not mentioning the ability to make use of various forms of reinforcement learning.
The aim of this paper is to review certain aspects that endow these systems with highly distinct properties.
Barrier to Entry: As discussed in great detail in ['If You Are Planning to Build a Gen AI Product, Read This.' - https://jpvasseur.me/if-you-are-planning-to-build-a-gen-ai-product-read-this], the path to productization for Gen-AI systems is expected to follow a different 'shape' compared to classic ML products. It begins 'easy,' allowing for a swift demonstration of the Proof of Concept (indicating a very low barrier to entry), followed by a longer tail due to the additional complexity of such Gen-AI systems (e.g., the number of components and their interactions). Significant effort is required to determine when the product has reached a stage where it can be safely deployed at scale, including the complexity of defining system-level efficacy metrics. This does not diminish the strong attractiveness of Gen-AI and their unprecedented scope in terms of applicability and addressable use cases. However, it is crucial to understand that a lower barrier to entry does not necessarily translate into an easier and shorter development cycle for high-quality products.
Reliability: Reliability poses a significant challenge. Consider a classification task used to detect the presence of malware, where reliability is tightly coupled with algorithm efficacy. The algorithm may trigger false positives or false negatives. However, the 'efficacy' of the algorithm is fairly well understood (assuming the test case is of good quality and representative) and synonymous with system efficacy. Moreover, the system is deterministic. The situation with LLM-based systems is rather different. Firstly, the tasks themselves may be harder to evaluate, and such systems are not only non-deterministic but also have the undesirable property of hallucinating. This issue is a hot research topic, with a plethora of techniques being proposed, including improvements to the model itself, prompt engineering, access to external knowledge via APIs, fact-checking, confidence scores, use of ensemble model approaches, and the use of multi-collaborative agents, among others. Although challenges to reliability are not insurmountable, they remain a core challenge for Gen-AI-based systems.
Interpretability: This may be a key concern. It's essential to understand the cause of a decision made by an ML model and how the outcomes have been produced. Lack of interpretability inevitably impacts trust. Moreover, improving models with low interpretability is highly challenging and may require trial-and-error approaches built upon strong efficacy measurement platforms. Note that interpretability is not specific to Gen-AI models such as LLMs or Small Language Models (SLMs); deep neural networks (CNNs, RNNs, ...) are also not easily interpretable, in contrast with classic ML algorithms such as Decision Trees or even Gradient Boosted Trees, which are extensively used for classification and regression tasks. Clustering algorithms such as K-Means and DBSCAN are also fairly interpretable. In contrast, Gen-AI systems like LLMs/SLMs are quite complex, and their interpretability is still an active area of research. This level of interpretability may be required for regulatory compliance to ensure the system is fair, ethical, and non-discriminatory. Even though such goals may be more achievable for 'smaller' models, models are one component of systems that are more complex, making the objective of LLM-based system interpretability seem far-fetched. The complex topic of interpretability will be discussed in a separate paper dedicated to epistemic humility and transparency.
The number of dimensions in the problem space refers to the overall system's parameters/variables that may influence its behavior and efficacy, often referred to as hyperparameters (e.g., architecture of neural networks such as the number of hidden layers, neurons, activation functions, or the depth of a decision tree, number of trees in a random forest, learning rate, or other regularization parameters, etc.). Several techniques can be used to tune such parameters, including grid search (exhaustive search through a specific subset of parameters), random search, Bayesian optimization (considering hyperparameter tuning as a Bayesian optimization problem), gradient-based optimization (when hyperparameters can be differentiated), or even evolutionary algorithms. To this end, a number of existing packages can be used, such as Auto-ML, Auto-sklearn, or H2O, to mention a few.
Gen-AI introduces even more challenges as the system's efficacy depends on numerous components, each with its own set of hyperparameters:
Prompting (engineering): instruction prompting, In-Context Learning (ICL) - n-shot learning, Chain-of-Thoughts (CoT), and various strategies related to the context window size.
Agent learning strategies: Tree-of-Thought (ToT), ensemble prompting, multicollaborative agent (e.g., AutoGen).
RAG: various strategies of retrieval, RETRO, RAPTOR, graph-based RAG.
Quality of data models.
LLM(s): a long list of models with different properties and efficacy metrics (GPTx, Llama, Orca, Mistral, Phi, Falcon, ...).
Self-improving/correcting techniques: a number of self-improving techniques adding other hyperparameters such as RL.
Use of various decoding strategies: beam search, temperature, ...
System Efficacy: As discussed in ['Focusing on Relevant Metrics for AI Systems!'], the efficacy of a Gen-AI (e.g., LLM or SLM) system requires in-house engineered metrics tests against a large number of test cases, in addition to various useful metrics specific to such models:
Latency (response time of the system).
Efficacy: the percentage of time.
Reproducibility (refers to the observed level of determinism).
Cost (number of tokens, ...)
Using strong data models: Often, Gen-AI systems gain real-time access to a myriad of other systems, providing access to a sheer number of sources thanks to open APIs. However, a commonly overlooked issue is the quality of the data retrieved via such APIs and used to feed the system via prompting (n-shot leaning). Take, for example, the Networking (cross-domain) APIs used by a networking troubleshooting engine; not only could the API be underspecified, but a given concept may also have different meanings according to the context, inevitably leading to confusion for the LLM handling the task at hand. For instance, the notion of 'Virtual Private Network' (VPN) could translate to VLAN for switching, MPLS VPN, or even micro-segmentation using SGT in security concepts. Thus, it may be necessary to normalize data using a common data model and schemas to disambiguate the semantics of the data. Deep engineer work in this are may often prove to be far more efficient than tweaking the algorithm itself or the prompting strategy.
Dealing with the pace of change: Is faster innovation always better? Yes, in some sense. Technology has rarely moved at such a pace, significantly outpacing product development. Unlike "classic" ML approaches, where new algorithms and optimization would occasionally emerge, Gen-AI has largely benefited from OPEN innovation, leading to an exponential growth in the number of innovations in ALL areas: algorithms, metrics, models, learning strategies, prompting strategies, RAG techniques, ... leading to an unmatched, unseen degree of complexity, especially regarding the ability to predict the overall system behavior. This raises another critical challenge: when should development cycles stop, leading to the much-needed phase of experimentation and code tuning as opposed to waiting for the next disruption? Not to mention the ability to maintain technologies in the future that may quickly become outdated and surpassed.
Multi-Agent Learning: The use of multi-agents in LLM-based architecture is likely to be one of the most promising avenues forward. Indeed, although not specific to Gen-AI systems, it represents a clear and promising avenue ahead. Having multiple agents collaborating to accomplish tasks may lead to the emergence of highly powerful systems capable of self-improvement, albeit with the risk of raising new challenges in terms of controller efficacy, easing interpretability, or other security issues. Still, such an avenue is highly promising.
Conclusion
The number of opportunities for Gen-AI-based systems is endless, and we have barely scratched the surface. Still, Gen-AI will not replace 'classic' ML algorithms used for classification, regression tasks, or even time-series forecasting. The aim of this review was to examine some of the characteristics of Gen-AI approaches compared to 'classic' ML, as they exhibit very different properties in some respects: despite a lower barrier to entry, the time to productization may not necessarily be shorter with Gen-AI. Reliability may quickly become a concern, although a number of novel approaches are beginning to emerge that will continue to improve reliability. However, it is hard to tell when such systems will be able to reach the same level of reliability as their 'classic' ML counterparts. Challenges such as interpretability and system efficacy assessment are significantly more difficult but could be surmounted by using new efficacy assessment and performance evaluation platforms with scientific rigor. None of these 'new' challenges is insurmountable, but new approaches are required for the development of such systems, which must be considered with care.
Figure 1: illustration of the architecture of a typical Gen-AI based system with one agent
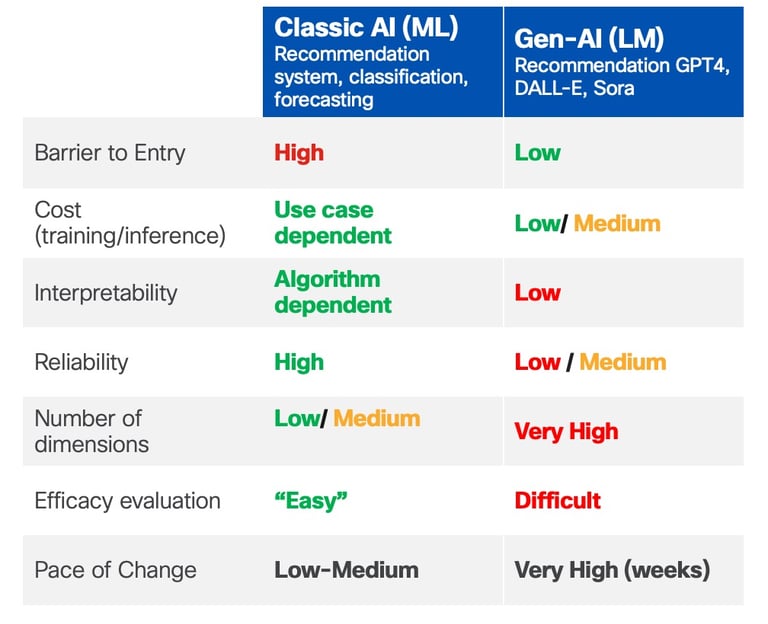
Figure 2: Classic ML vs Gen-based systems comparison