
AI and Neuroscience: the (incredible) promise of tomorrow
JP Vasseur (jpv@cisco.com), PhD - Cisco Fellow, VP Engineering ML/AI Release 1 – August 2023
The brain is slow, unreliable, yet still the most complex, powerful, and energy-efficient device in the universe …
Highly sophisticated (biological) hardware: made of different structures such as the reptilian complex, limbic systems and neo-cortex, the human brain is made of 80 billion neurons (and a similar number of glia cells) interconnected via 1014 synapses, organized in dozens of brain networks accomplishing a myriad of (complex) tasks and forming a highly dynamic system. Each neuron is by itself a complex, dynamic structure capable of sophisticated signal processing, and there are dozens of types of neurons with different architectures. Neurons communicate using electric and chemical signaling (neurotransmitters, of which there are hundreds of types). More than 100 miles of “wires” (axons) making one of the most complex interconnected systems of the universe.
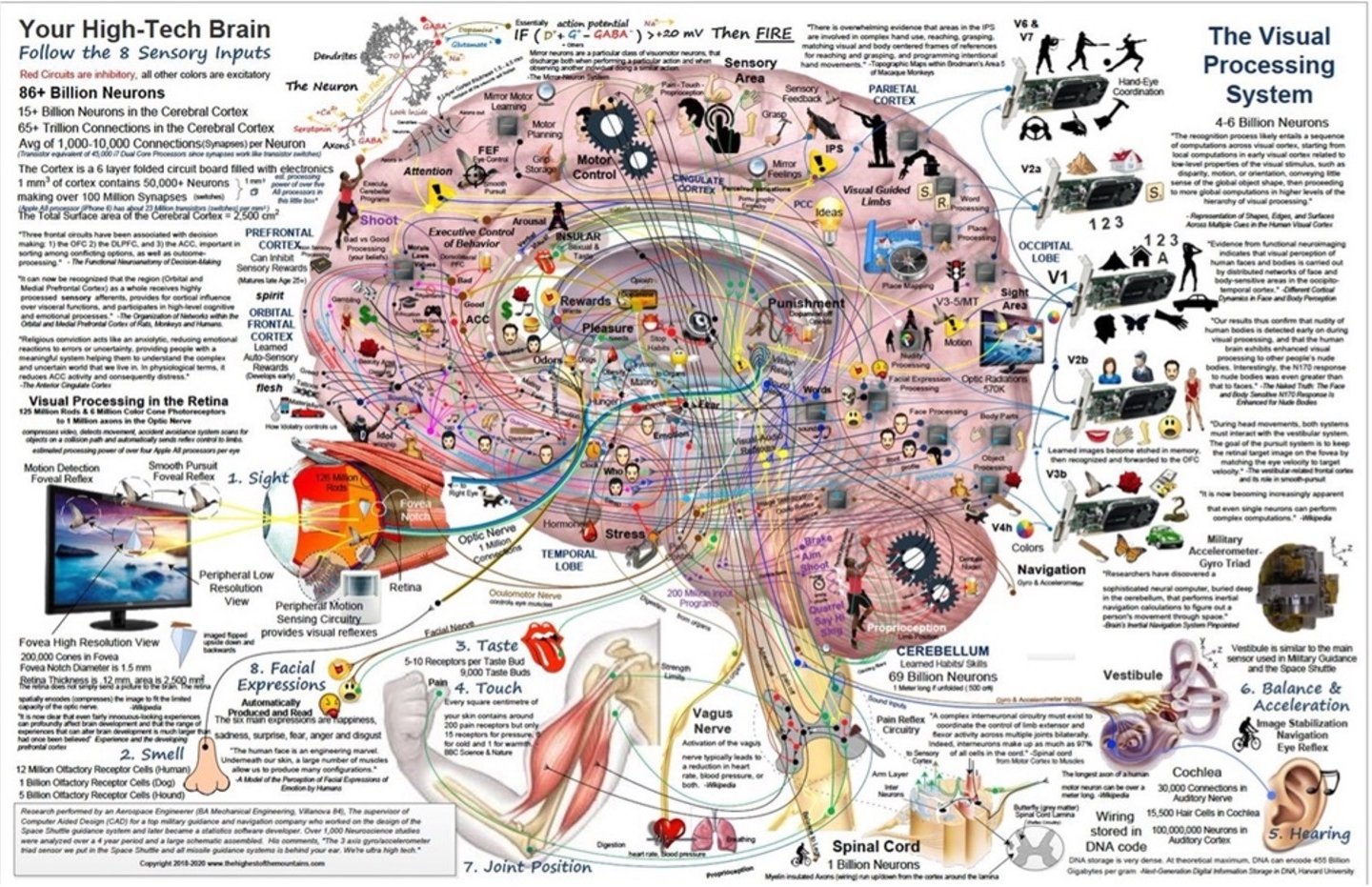
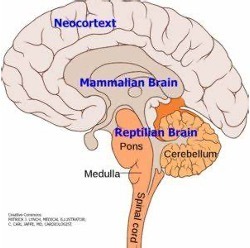
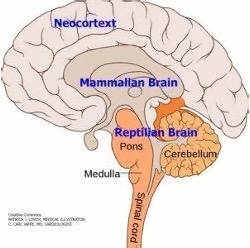
The brain is mainly organized into three components: the reptilian complex (including the brainstem and basal ganglia), which controls our most basic functions; the limbic system (comprising the hypothalamus, amygdala, hippocampus, thalamus, and cingulate gyrus), responsible for homeostasis, emotion regulation, memory, and the interconnection of hubs for thought and behavior; and the neocortex, the most recent development, responsible for a myriad of higher-order functions such as vision, audition, language, and complex tasks like reasoning, prediction, and planning (specifically in the pre-frontal cortex). Such an organization is the result of 350,000 years of evolution.
Highly Dynamic/Plastic: From an early age, the brain builds new connections especially during 'critical periods’ and removes unused connections (pruning). The brain is constantly evolving thanks to synaptic plasticity (new connections forming and driven by tasks (according to the famous Hebb’s rule “What fires together, wires together) while others are removed when unused or during sleep (downscaling). The brain can even generate new neurons thanks to neurogenesis (at least in some regions). The human brain is so plastic that it is even capable of complete rewiring during aging and after unfortunate stroke events. Such synaptic plasticity is now known as happening during the entire duration of life.
Organized in Specialized (Yet Interconnected) Brain Networks: There are several networks handling a variety of functions such as the visual network, auditory network, limbic network (emotion, motivation, and memory formation), sensorimotor network (integration of sensory and motor commands), dorsal attention network (directed attention and goal-oriented behavior), ventral attention network (attention reorientation), frontoparietal control network (novel tasks), language network, cerebellar network (motor coordination and learning, sensory integration, motor command correction and even cognitive functions), and the famous, well-studied default mode network, just to mention a few of these networks in the brain. Note that different functional networks does not necessarily imply that their biological structure is vastly different.
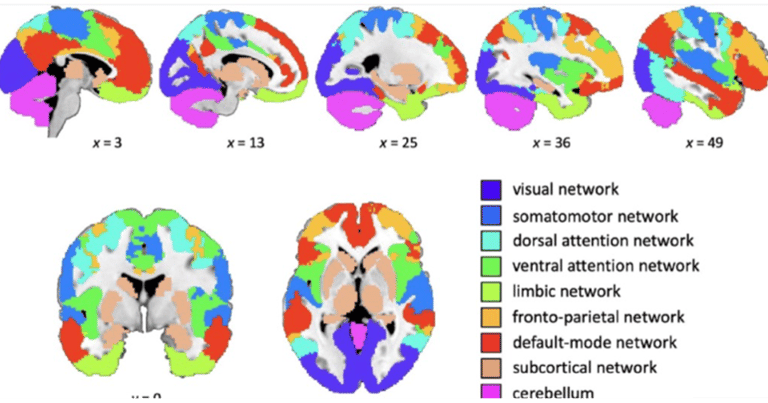
Capable of Multi-modal Learning and Task Generalization, from Very Small Amounts of Data/Information: The brain is capable of multi-modal learning and task generalization using a very small amount of information; indeed, a human can acquire new skills using a remarkably small 'training dataset,' at least compared to the vast amount of data required for training ML/AI systems. Moreover, the brain learns without forgetting previously acquired skills, a phenomenon not always exhibited by digital systems. In many digital systems, a Machine Learning (ML) algorithm trained to solve task A may degrade in efficacy on task A when trained to solve a second task B, a phenomenon known as catastrophic forgetting. As of today, this issue has been partially solved thanks to multi-task learning and other techniques, although some of these methods may be greedy and not cost-efficient.
Energy Efficiency: Last but not least, the brain accomplishes all of this with just 25 Watts of energy consumption! The issues of energy efficiency has been without a doubt a huge source of inspiration for reinventing new hardware and software in digital system (as discussed below) and will continue to be.
Now consider Artificial Intelligence
New Generation of Hardware: Just for the sake of illustration, a single NVIDIA A100 GPU is equipped with 80GB of RAM and delivers 15.7 TFLOPS (15.7 1012) of computation power thanks to 6,912 cores and 54 billion transistors (using 7nm TSMC technology, while 4nm processors are under development). Although this has been a topic of activate debate, the number of operations performed by the brain is estimated to be between 1016 and 1017 per second.
A Remarkable Journey in AI: Overcoming Challenges, Facing Disillusions and Achieving Breakthrough: Over the past 50 years, ML/AI technologies have been constantly evolving thanks to the development of a myriad of new algorithmic approaches, including statistical and Machine Learning (ML) models. New learning approaches have emerged, such as supervised, unsupervised, semi-supervised, reinforcement learning, federated learning, and self-supervised learning. One must highlight a few real breakthrough advancements, such as Convolutional Neural Networks (CNNs), broadly used in vision; Deep Neural Networks, used in a number of applications; and more recently, one of the biggest breakthroughs in AI history: Generative AI, at the heart of which are transformers (along with other technologies) have led to Large Language Models (LLMs) and various technologies used to create different types of output, such as audio, video, and images.
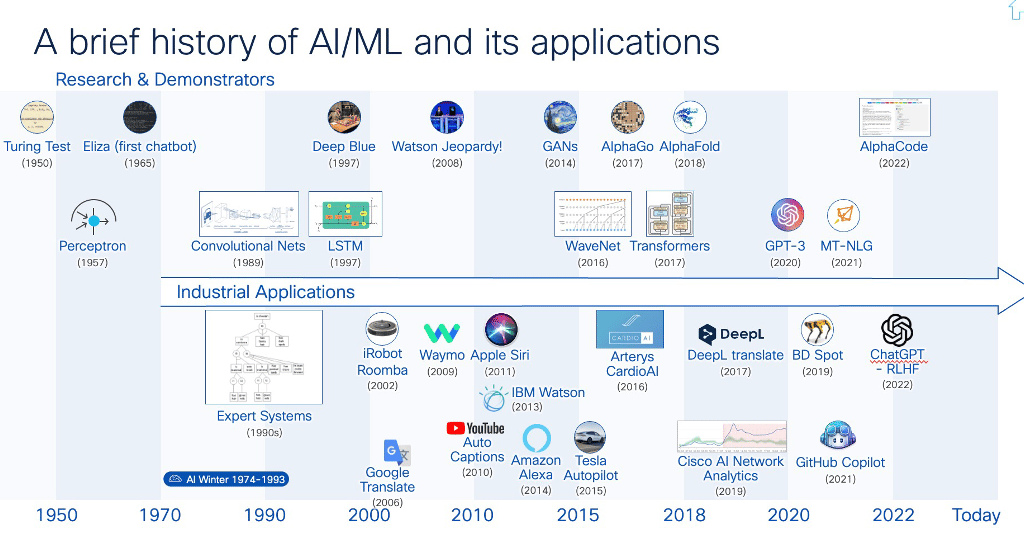


Innovation with Large Language Models (LLMs): Thanks to learning from trillions of words from public datasets, LLMs have demonstrated their ability to perform tasks ranging from text summarization, translation, advanced programming, sentiment analysis to (more recently) complex multi-step reasoning and planning. LLMs utilize technologies like Transformers and attention mechanisms coupled with prompt engineering and tuning, Retrieval Data Augmentation (RAG) extracting knowledge from vector/semantic databases thus providing a form of long-term memory, to mention a few. Emerging properties of LLMs seem to show the ability for such models to reason and plan (although still debated), attributes previously thought to be exclusively human. These models can even align with human values using RLHF (Reinforcement Learning from Human Feedback) and RLAIF technologies (Reinforcement Learning from AI feedback). Moreover, LLMs seem to be capable of learning from small datasets used the combination of n-shot learning in prompt and fine-tuning of pre-trained foundational models. The ability to learn from a small amount of database had been until then one of the main challenges of ML. LLMs continue to evolve at a pace that had never been seen over the past 30 years of technology within the high-tech industry.
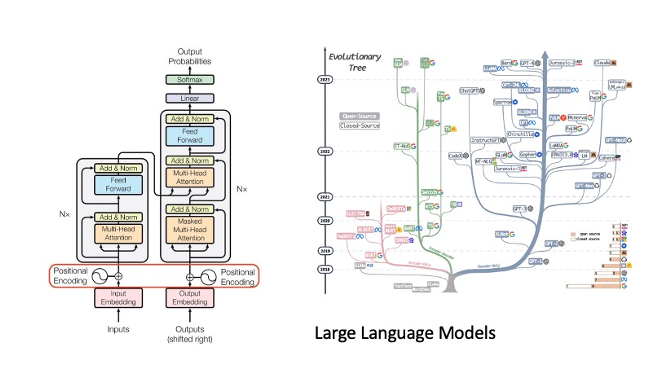
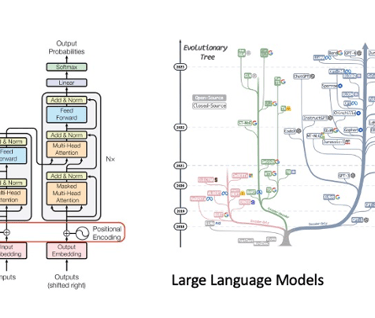
A plethora of models with various sizes and capability continue to emerge but just consider the case of (currently) one of the most powerful foundation models: GPT-4. Although the actual numbers are not disclosed, it is thought that GPT-4 comprises 1.8 trillion parameters across 120 layers, 10x larger than GPT-3, and supposedly trained on about 13 trillion tokens. It employs a Mixture of Experts (MoE) model with 16 experts, each having about 111 billion parameters. Utilizing MoE allows for more efficient use of resources during inference, needing only about 280 billion parameters and 560 TFLOPs, compared to the 1.8 trillion parameters and 3,700 TFLOPs required for a purely dense model. The training setup may have involved roughly ~25,000 A100s for 90-100 days. Another model such as Llama-70B (from Meta) has 70 Billions parameters and has been trained on about 2 trillion tokens and support 4K token context sizes. Other models such as Claude-2 (~ 860Millions parameters) relying on the concept of Constitutional AI and support context window of 100K tokens.
New techniques continue to emergence so as to improve efficiency while reducing the amount of resources required during training and inference of LLM: for example PEFT (Parameter Efficient Fine Tuning) could be used to fine tune models while only updating a small set of weights; other approaches have been developed to train a smaller model using a larger (more complex) model thanks to “Knowledge Distillation”. Other techniques could be used to reduce the required memory footprint via “Quantization”. This entire document could be dedicated to listing all such techniques and a separate White Paper (WP) will be devoted to LLM.
Emergence of Specialized Hardware: Although a number of challenges still remain, and neuromorphic computing has not yet delivered on its promises, specialized neuromorphic hardware has begun to emerge. Neuromorphic hardware is based on the paradigm of neuromorphic computation, more closely emulating the brain, especially with regards to neuron communication using spikes (see also Spike Neural Networks). This leads to greater efficiency in terms of learning and energy.
On the dark side, one must admit to a poor understanding of the brain but also (many) AI systems: despite incredible progress over the past few decades thanks to the development of advanced technologies, the brain still harbors a number of secrets, such as how memory really works (including the famous N-grams), the role of sleep, how thoughts are formed, consciousness, and high-order functions such as planning, complex reasoning, or even the process of learning (it now seems clearer that learning is multimodal and self-supervised, still many mysteries remain). On the AI side taking LLM as an example, their architecture is well understood, but the fundamental reasons why they work are poorly grasped. They are trained and used using very empirical methods, sometimes close to what might be called 'black magic.' Whether such models are merely advanced statistical parrots or if they possess a strong understanding of the world (which is not unlikely) is also an area of active research (with strong hopes to better understand / retro-engineer the algorithm learned by a model thanks to the nascent field of mechanistic interpretability for example). Emergent properties seems to show the ability to use LLM as generic patterns matching engines.
Consider the power of bringing together AI and Neuroscience (sometimes referred to as neuro-inspired AI or NeuroAI) to build a virtuous cycle leading to unprecedented scientific discoveries and innovations.
AI Helping Neuroscience
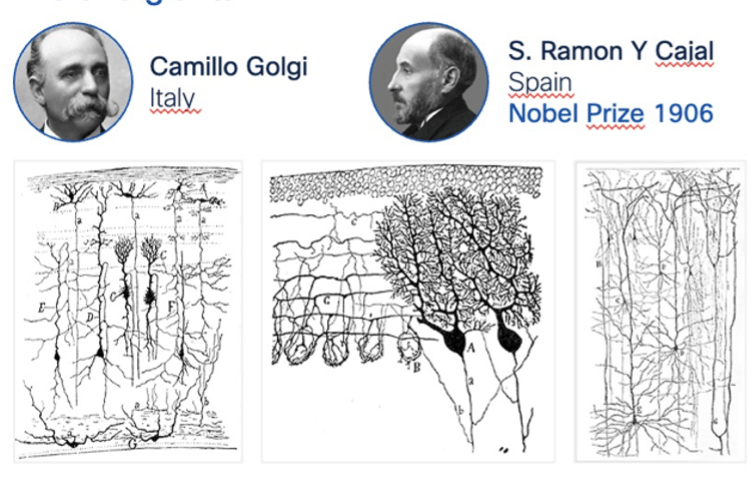
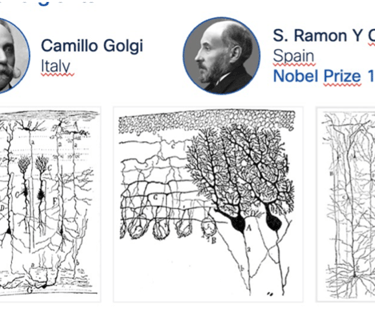
Remarkable progress since the first drawing of Ramon Di Cajal who still remains one of the most influential neuroscientists in history: a broad range of tools is now available to study the brain: fMRI, EEG, MEG, TMS, cell recordings, optogenetics, 2-photon microscopy, each with different spatial and temporal resolutions. These tools produce vast amounts of data. Machine Learning (ML) and AI algorithms have played a considerable role in the data analysis and understanding of such a complex system: supervised learning, unsupervised such as clustering and dimensionality reduction, deep time-series analysis, graph-based models, Bayesian methods or causal inference models to mention a few.
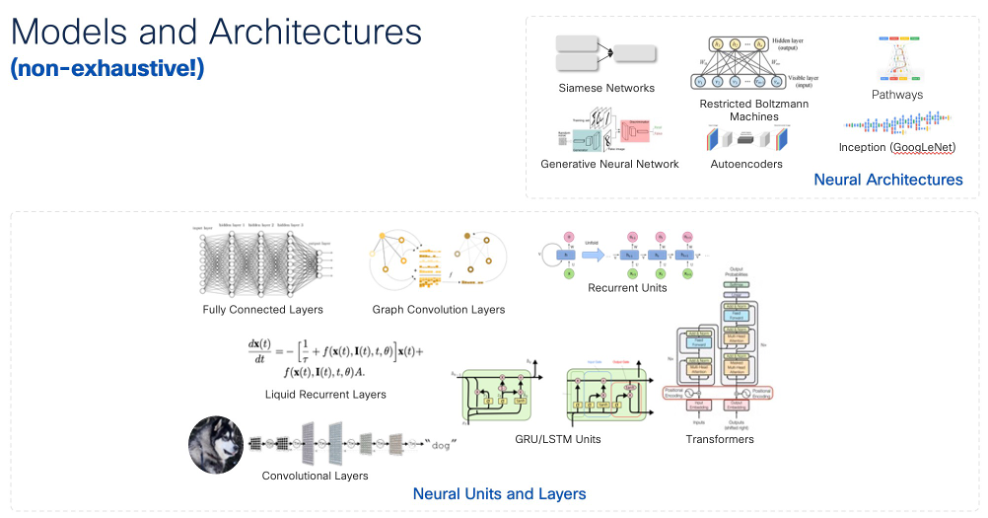
The number of ML/AI algorithms used to understand the brain in Neuroscience is endless. Here are a few examples:
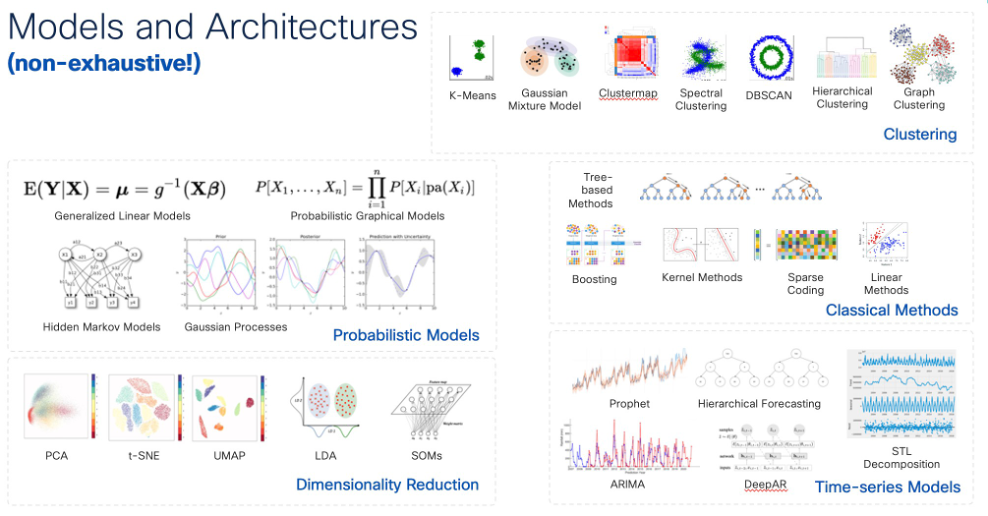
· Dimensionality Reduction refers to algorithms used to transform high-dimensional data (sometimes with hundreds or even thousands of dimensions) into a lower dimension, while striving to retain most of the information. Dimensionality reduction is employed across various fields such as ML, AI, and Neuroscience to simplify analysis, reduce noise, make data visualizable, and improve computational efficiency. As illustrated in the figure, a plethora of algorithms have been designed, each with its unique advantages and disadvantages. Examples include Principal Component Analysis (PCA), Self-Organizing Maps (SOM), Uniform Manifold Approximation and Projection (UMAP), Diffusion Maps, and ML Autoencoders, among others. For instance, PCA has been utilized to identify temporal and spatial patterns in EEG or fMRI signals. ICA is used in fMRI to segregate multivariate signals into additive and independent components, thus separating signal from noise. Analyzing neural signals from electrode arrays, which record the activity of hundreds of neurons, is challenging. UMAP can project this data into a lower-dimensional space, enabling visualization of activity patterns and clustering neurons based on similar firing activities.
· Clustering is a widely-used class of algorithms that groups similar data in potentially high-dimensional spaces based on some measure of distance. Clustering can, for example, be employed with fMRI data for brain parcellation based on functional connectivity patterns or to identify brain regions that co-activate and are thus likely to communicate. Additionally, it can categorize single neuron recordings based on attributes like spike shape or amplitude. Clustering is also useful for grouping fiber tracts obtained from DTI, aiding the study of White Matter Pathways.
· Decision Trees are powerful algorithms that have been employed for diverse tasks, including classification and regression. They are especially efficient with tabular data and are highly interpretable, especially when compared to Neural Networks. For instance, such algorithms have been leveraged to predict the severity of brain injuries using clinical data and imaging features, or even to classify brain states during cognitive tasks based on EEG signals.
· Time Series Analysis has been instrumental in Neuroscience. For instance, fMRI is used to analyze the time series of the Blood Oxygen Level Dependent (BOLD) signal, which acts as a neural activity proxy. Various ML algorithms have been employed here, such as time series clustering, ICA (to separate multivariate signals), and Neural Networks algorithms to analyze data sequences/events. Others include Hidden Markov Models (for analyzing transitions between states) and techniques to analyze time series correlation (e.g., Pearson coefficient, Auto-correlation, Dynamic Time Warping, or Mutual Information). STL (Seasonal and Trend Decomposition) algorithms have also gained traction. Numerous time-series models have been applied in the field of Neuroscience for EEG, fMRI, and MEG time-series, including Auto-Regressive Models, ARIMA, Recurrent Neural Networks, and State-Space models.
· Neural Networks: These algorithms have been widely applied in numerous neuroscience areas. For instance, Convolutional Neural Networks (CNN) are utilized for analyzing MRI, fMRI, and EEG to detect patterns, identify diseases, and predict clinical outcomes. RNN and LSTM are adopted to dissect complex EEG and MEG time-series. Neural Networks have also found utility in decoding intricate neural activities and predicting treatment efficacies.
These advancements have allowed for deciphering some of the underlying mechanisms of the brain.
Here are several groundbreaking and highly promising applications of AI in neuroscience:
Brain Anatomy (Connectomics): Significant progress has been made in understanding brain anatomy and topology using ML/AI. The internal brain topology, also known as connectomes, is a burgeoning field. Currently, the only fully mapped connectome is that of C. elegans, comprising 302 neurons and 7,500 synapses. The next potential targets might be the connectome of a mouse, which consists of 70 million neurons, and possibly, in the future, the human brain. These advancements could provide deeper insights into "how the brain works," insights that might be elusive using traditional, non-ML methods.
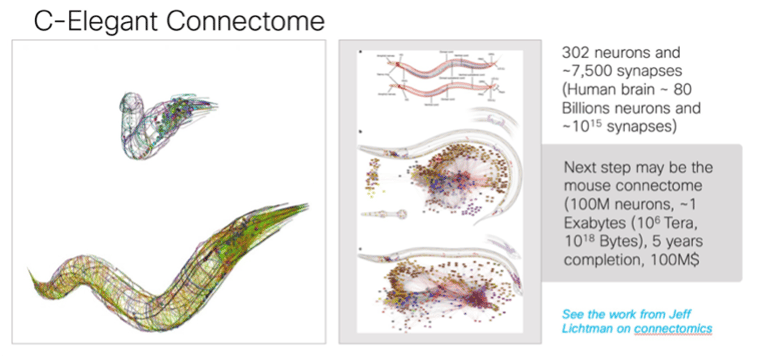
· Brain-Computer Interface (BCI): There has been remarkable progress in BCI over recent years, fueled by AI/ML technologies. Advanced neuro-prostheses have been developed using ML algorithms trained to decode neural activities from motor regions. These decodings enable control over robotic arms or legs and interpret motor intentions to pilot robotic components. AI has been employed to interpret thought patterns for locked-in patients. Furthermore, ML algorithms have been designed to interface with games through the analysis of non-invasive EEG signals. Predictive coding has also been explored to anticipate an intention before the actual command is given. Various algorithms aim to improve the signal-to-noise ratio by removing EEG artifacts, thus enhancing BCI.
· Understanding Vision and Audition: ML/AI algorithms have played a pivotal role in comprehending vision and hearing. ML models have been trained to reconstruct visual and auditory stimuli, offering a glimpse into what the brain perceives and hears. Decoding such stimuli paves the way for BCI development to aid visually impaired individuals. For instance, a camera might capture an image and convert it into tactile or auditory signals, providing alternative ways of "seeing." Enhancing our understanding of auditory signals can lead to improved cochlear implants, offering superior speech recognition and sound localization. In the future, this might also lay the foundation for artificial vision and auditory systems.
· Psychiatry: Over the past decade, psychiatry has increasingly leveraged ML/AI for identifying psychiatric diseases (e.g., schizophrenia), predicting susceptibility to specific diseases, and distinguishing between ailments with similar symptoms. ML/AI models can facilitate personalized medicine, predicting a patient's response to treatments and monitoring therapeutic interventions.
· Drug Development: ML/AI technologies are revolutionizing drug development. The groundbreaking work of AlphaFold in predicting protein structures (known as protein folding) from DNA sequences has been a leap towards new drug discoveries. This innovation benefits not just pharmacology but also broadens our understanding of diseases and biological research. Additionally, AI has been employed to gain insights into drug interactions, a notably complex domain.
· Surgery: The surgical field has begun integrating ML/AI, especially for preoperative planning where visual assessments can be challenging. This integration extends to robot-assisted surgeries, intraoperative image recognition, and more. For instance, in epilepsy surgeries for patients resistant to pharmacological treatments, ML algorithms have been trained to pinpoint seizure onset zones.
Neuroscience helping AI
Such a virtuous cycle has already started long time ago. Wasn't the first neural network inspired by the seminal discovery of vision processing in the brain by Hubel and Wiesel (Nobel Laureates, 1981) 40 years ago?
Outcomes in neuroscience have inspired AI research in a number of areas, leading to algorithmic improvements such as Deep Neural Networks (a foundational block of ML), Natural Language Understanding (NLP), the emergence of new bio-inspired algorithms and hardware (neuromorphic computing), ethical AI (thanks to a better understanding of human values and cognition), and the advancements in robotics.
Several interesting examples include:
· Neural Networks: The entire family of Neural Networks (NN) algorithms has been heavily inspired by the brain. Although they are a highly simplified version of their biological counterparts, neural network architectures, like Convolutional Neural Networks and Recurrent Neural Networks, are founded on our understanding of brain structure. It's worth mentioning that the use of gradient descent to tune weights in artificial neural networks might not mirror the algorithms used by the brain to drive synaptic strength. Several theories exist suggesting that the brain is unlikely to implement gradient descent due to factors such as the strong directionality of neurons. Anecdotally, some artificial NNs have implemented mechanisms similar to STDP (Spike-Timed Dependent Plasticity) for weight fine-tuning.
· Reinforcement Learning: Reinforcement Learning (RL) in AI draws inspiration from the brain's reward system. In its simplest form, RL involves an agent taking actions to achieve a goal, guided by the expected cumulative reward. The definition of the reward rests with the RL algorithm's designer. Key components include the Value Function V(s) (the expected cumulative reward from state s and the Action-Value function Q(s,a) (the expected cumulative rewards from state s after taking action a. RL systems balance exploitation with exploration. Algorithms such as DeepMind's AlphaZero, which masterfully handles games like Go, employ a blend of Monte Carlo Tree Search (MCTS) and Deep Neural Networks. Temporal Difference (TD) Learning, an RL variant, estimates rewards by comparing value estimates at consecutive time steps.
· Neuromorphic Computing: Entirely driven by the study of the brain and neuroscience, neuromorphic computing seeks to emulate brain functions in silicon. For instance, Intel's latest chipset, Loihi 2, supports up to 1 million neurons, roughly the number found in a bee. Various projects, such as BrainScales, Spinnaker, Loihi, and the more recent NeuRRam, are advancing this field. A primary goal of neuromorphic computing is energy efficiency, which it achieves through principles observed in the brain, like non-clocked signal processing using spikes.
· Attention Mechanisms: One core mechanism used by Generative AI allows models to focus on specific parts of input data. While not fully understood, the brain can focus attention on certain stimuli while filtering out others, likely influenced by the Prefrontal Cortex (PFC). In vision, for instance, the parietal cortex plays a role in directing attention. Self-attention in transformer models, such as GPT and BERT, has been pivotal. With self-attention, each input element of a sequence can focus on other elements based on dynamically learned weights reflecting their relevance. Attention mechanisms have significantly impacted ML/AI by improving efficiency, handling longer input sequences, and enhancing model interpretability.
· Hierarchical Memories: Modern AI systems, like Large Language Models (LLMs), come equipped with short-term memory (scratchpad), long-term knowledge databases, and information retrieval mechanisms. This structure, though distinct from human memory retrieval, complements the innate memory embedded within neural networks.
Undoubtedly, neuroscience will continue to influence, and possibly reshape, the software and hardware underpinning AI algorithms, pushing them towards greater energy efficiency and multitasking capabilities.
The promise of tomorrow
Predicting the future in an area that is, without a doubt, the most rapidly evolving in history is certainly not reasonable. Still, it seems quite obvious that such a virtuous cycle exists between AI and Neuroscience, and one can certainly list a few highly promising interplays between AI and Neuroscience.
Bio-inspired hardware and software: Many inventions have been driven by biomimicry. As Linda Buck, a Nobel Prize laureate, once said, “The biological mechanisms that are used are usually far more elegant than the theories that people come up with.” Examples of such innovations include the bullet train, whose nose was inspired by the shape of the kingfisher’s beak; adhesives inspired by geckos' ability to effortlessly climb walls and ceilings; and the Ant Colony Optimization algorithms (ACO), which were inspired by the behavior of ants in finding paths from their colony to food sources. The number of bio-inspired inventions or development is countless. The brain, arguably the most complex and advanced entity in the universe, is not an exception.
Without a doubt, new AI systems will benefit from a deeper understanding and mimicking of the brain. This will lead to innovative approaches in both hardware and software that are more capable, energy efficient and parallel. For instance, several studies have shown that Neural Networks trained for specific tasks (e.g., vision) and then optimized to predict biological neural networks outcomes performing the same task show a significant improvement in performance. Numerous research areas are in progress, involving a potential rethinking of software and hardware. Such approaches may use some fundamental properties of the brain in the near future, such as spiking communication, sparsity, neuron-based communication processing and memory storage and continuous learning.
The whole field of neuromorphic computing has been driven by the hope to develop hardware closely inspired by the human brain that could be far more efficient. Other research areas have led to neuro-inspired algorithms that exhibit highly promising results by various companies (e.g., Numenta). Some research is even driven by the Free energy principle in the brain, where biological neurons could be trained to execute (at least for now) simple tasks such as playing the game of Pong (e.g., Cortical labs).
Let’s investigate more precisely several aspects …
Energy efficiency: LLM has opened the door to numerous breakthrough innovations and an unprecedented number of applications having a remarkable impact on many industries. That being said, one cannot overlook the issue of energy consumption. Not only are these models quite greedy at training times, but their use at inference also raises considerable challenges in terms of energy consumption (the estimated power consumption of ChatGPT in January 2023 was the one of 175,000 persons). Despite a number of attempts for solving such challenges, all envisioned approaches are orders of magnitude less efficient than biological systems: with 86B Neurons and 1014 synapses, considering that a single spike consumes about 10-12 Joules and firing rates vary between few to 1,000 /s (sensory), the whole brain consumes roughly 25 Watts! How can the brain perform such complex tasks using an incredibly complex biological device while only requiring 25 Watts? For the sake of illustration, simulating 1 Billion very simple neurons on 65.000 processors on the K Computer in Japan (1% “Brain” Size) required, 13 Megawatt, 1500x slower than biology and 10 billions times less efficient than the brain.
Deciphering the Science of Learning
· Efficiency and generalization: The combination of self-supervised learning and efficient model fine-tuning of LLM has shown how foundation models can be trained using massive amounts of data, then refined for specific tasks using small datasets, a process known as fine-tuning or even less data inserted in prompt (“in context Learning”). Still, the brain seems to be able to learn much more efficiently, with a unique capability for generalization and without catastrophic forgetting (learning a given task does not lead to forgetting previously learned tasks). Many research efforts are on their way to understand whether LLM may have some learning generalization abilities (e.g. “Grokking”, mechanistic interpretability). Understanding how and what has been learned is also a path forward potential “safer” AI.


· Multi-modal learning: Although we seem far from lacking text-based training data for LLM, humans inherently learn from multiple modalities such as text, vision, and hearing. Although extremely large text corpuses are available it is unclear whether text is enough to “learn the world”. The ability to train models using a variety of inputs will undoubtedly open the doors to a new era of AI models, getting closer to the ability to understand the world similarly to how humans learn about the world. Models trained on multiple modalities are on their way.
· Using World-based models: The brain is known to be highly driven by its ability to predict (see predictive coding). Will future AI models be able to predict the consequences of their actions on the world, and use sensing for dynamic adjustments when predictions are incorrect, similar to how the brain is believed to operate? Are there other models to represent the world and thus expect such system to truly understand the world: text-based training, such as with LLM, might represent a step in this direction; in fact, text-based training could potentially be viewed as creating a world representation, a topic currently under research. Studies on the emerging properties of LLM may reveal exceptional abilities. This is clearly an area where both AI and Neuroscience can and will benefit from mutual collaboration.
· Continuous Learning: Consider a model trained to accomplish a given task such as a Neural Network. The training phase makes use of training data in order to compute the weights of the model until a function reflecting the model performance (called the loss function) seems to be “optimal enough” (reaches a plateau); at this point if the model performance is not satisfactory, additional (potentially more diverse) data may be required so more training, the model architecture may be refined, etc … Once trained, the model is ready for use and the learning process stops. The integration of additional knowledge does require a re-training. With LLM, it is possible to fine-tune a model using a smaller amount of data while modifying a much smaller number of parameters (weights) thanks to techniques such as LoRA briefly discussed above, while new knowledge may be exploited at inference in the prompt. In contrast, the brain naturally performs continuous learning. Developing AI approaches capable of continuous learning would be a major advancement for AI, inspired by the brain.
Enhancing models of Neurons in Neural Networks more closely inspired by biological neurons: as of today, Artificial Neurons although indeed inspired by biological neurons are over-simplistic. An artificial neuron is a simple mathematical function that computes the weighted sum of input values (continuous variables) received from other neurons and runs an activation function to provide an output. Various activation functions can be used (sigmoid, hyperbolic tangent, rectified linear unit). Many of these neurons are linked in layers to form a Neural Network that can accomplished extraordinary, advanced tasks
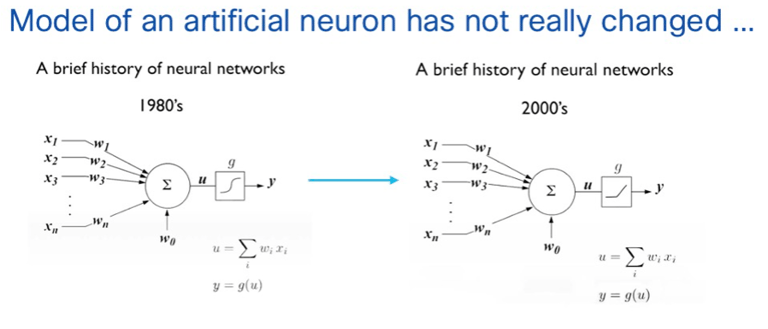
In contrast, although a biological neuron also receives signals from other neurons and provide an output, their structure and architecture is highly more complex.
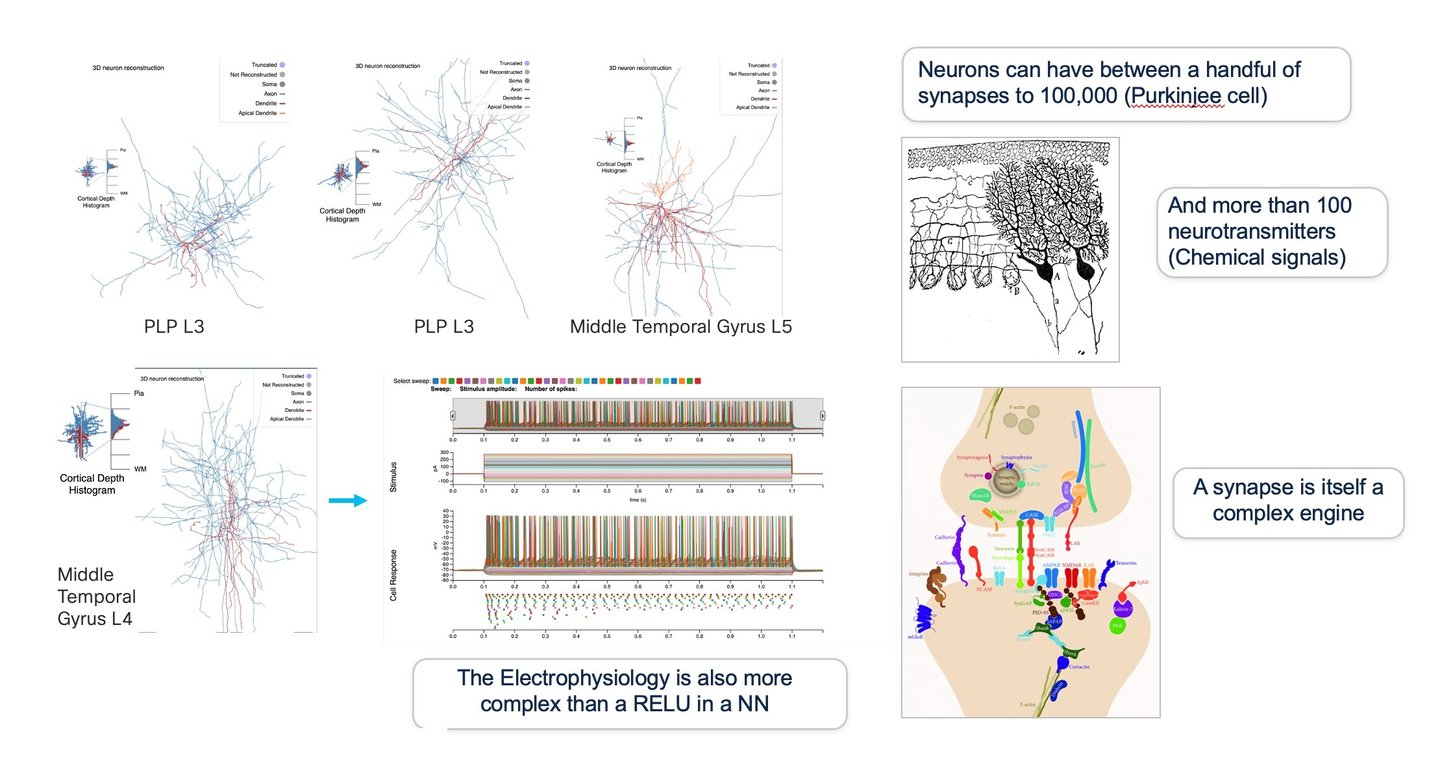
There are many types of neurons in the brain, such as sensory, motor, and interneurons, each with distinct structures and architectures like multipolar, bipolar, and unipolar. These neurons possess synapses that can range from a few to tens of thousands, communicating through both electric and chemical signals. There are hundreds of types of neurotransmitters, including Glutamate, GABA, Dopamine, Acetylcholine, Serotonin, Neuropeptides, Noradrenaline, and Endorphins, to name just a few. Even a single synapse is an incredibly sophisticated and dynamic entity. In a biological neuron, computation is not limited to the soma; it also occurs in the neuron's dendrites (dendritic computation). As such, dendrites can perform intricate computations on their own and are not the simple conduits they were once believed to be. Dendrites contain various ion channels that can produce dendritic spikes. Moreover, because of the active role dendrites play, the combined effects of multiple synaptic inputs might not result in a linear summation, unlike in a digital neuron. We now understand that synaptic plasticity can vary within a neuron, either being localized or widespread. Additionally, it's believed that dendrites integrate signals both spatially and temporally, leading to linear and non-linear effects. Some studies have even suggested that a 5-8 layer deep neural network (DNN) is required to approximate a single biological neuron, with dendrites conceptualized as spatiotemporal pattern detectors.
Using multi-modal inputs: Many experiments have been conducted in which ML algorithms were used to assess mood and the psychological state of a human, utilizing vision and voice. Recent experiments started to make use of multimodal LLM input (e.g., multimodal paralinguistic prompting with LLM).
Memory: Memory has been a long-studied topic in Neuroscience and is known to involve a number of brain structures such as the hippocampus, temporal lobes, basal ganglia, cerebellum, prefrontal cortex (for working memory), and the amygdala, to mention a few. It is worth mentioning that the hippocampus also handles other critical tasks such as spatial navigation (e.g., using grid cells, place cells, border cells, directional cells, head direction cells, etc.), knowing that both tasks (memorization and spatial navigation) are likely tightly related.
There are several stages involved in memory, such as encoding, consolidation (moving to long-term memory), storage (in different regions of the brain depending on the type of memory), and retrieval. The process of retrieval (memory reconstruction and retrieval) also involves a number of brain structures, each in charge of storing various aspects of the memory. One path toward deciphering the underlying mechanisms of memory has been the engram, supposedly a "trace" of memory representing how memory is stored in the brain (e.g., strengths of synapses, etc.), a topic that has been studies for years. In AI systems, the process of memory is still poorly understood, and many research efforts are aimed at understanding what and where information is stored in models such as LLM, which by way are now equipped with hierarchical memories (“backed in” (the model itself), short-term (scratchpad in prompt) and long-term using knowledge database equipped with Retrieval Augmentation Generation). Once again, memory in AI and Neuroscience is an area that could be highly beneficial to each other.
Resistance to noise is yet another area where AI systems could benefit from insights in neuroscience, given the brain's remarkable resilience to noise.
The concept of "noise" merits clarification as it can have various defined meanings. Generally speaking, noise refers to imperfect communication where the intended signal is distorted by a random, undesirable interference, potentially leading to significant undesirable effects, impacting both the channel's capacity and system reliability. In the context of communication systems, noise can arise from electromagnetic interferences, leading to corrupted signals and communication errors. In machine learning, "noise" denotes inconsistencies or randomness in data, such as errors in input features due to inaccurate telemetry, mislabeled data, or algorithmic factors (e.g., the random deactivation of neurons via dropout). In sequence models, temporal noise might arise from inconsistencies or random measurements. Some forms of noise, like adversarial attacks, might even be intentional. When considering the brain, noise can manifest in various forms: neural variability (inconsistent responses to a similar signal), synaptic noise (since the release of neurotransmitters across synapses is inherently stochastic) and input sensory processes that are exposed to a myriad of stimuli, not all of which are relevant to a specific task.
Numerous strategies exist to tackle noise across communication systems, machine learning/AI systems, and the brain. Communication systems employ error codes to detect compromised communication. Corrections can be implemented through retransmission (based on explicit or implicit acknowledgment), especially when the communication doesn't demand real-time data reception, error correction (which adds overhead), or selecting optimal channels in cases of packet duplication. In machine learning, various techniques, such as controlled noise addition during training (e.g., data augmentation), regularization, ensemble methods, dropout in neural networks, and adversarial training, can address noise.
The brain has evolved several strategies to manage noise. A key approach is the introduction of massive redundancy. Parallel communication, where information is relayed through multiple pathways, helps counteract the adverse effects of noise. Synaptic plasticity enhances resilience, and frequently used pathways see increased synaptic strength (Hebbian Theory), making them less susceptible to noise—a mechanism absent in both communication systems and ML algorithms. There seems to be evidence that the brain uses error correction codes in neural communication (a study published in the journal "Nature Neuroscience" in 2011 showed that the brain uses a binary code to represent information, and that it could use a form of error correction coding known as a Hamming code to detect and correct errors in neural communication). Furthermore, the brain's use of multimodal integration, where it can disambiguate distorted information from one sense by referencing another, further bolsters its resistance to noise. Clearly, when it comes to resistance to noise, both neuroscience and AI stand to benefit from shared insights.
The brain's extraordinary resistance to noise highly contrasts with the undesirable sensitivity of artificial neural networks to adversarial attacks. These attacks involve subtly altering input data to deceive the model and produce incorrect outputs, such as misclassifications. Various techniques, both white-box and black-box, have been employed for this purpose, including Generative Adversarial Networks (GAN), Fast Gradient Sign Method (FGSM), DeepFool, and Zeroth-Order Optimization (ZOO) attacks. While defense strategies like adversarial training, Variational Autoencoder (VAE) gradient masking, and distillation techniques are under development, this remains an active area of research. Neuroscience might offer insights to assist AI in this domain.


The extraordinary plasticity of the brain stands in stark contrast to the static nature of AI. In the late 1960s, Marian C. Diamond was among the pioneering neuroscientists who unveiled the profound plasticity of the brain. She demonstrated that rats raised in enriched environments had thicker cerebral cortices than those in deprived settings. This finding was revolutionary, as it debunked the prevailing notion that environmental influences couldn't alter the physical composition of the brain beyond a certain age. Subsequent research in neuroscience has underscored the brain's dynamic nature. For instance, in the initial years of life, synaptic connections form at an astonishing rate of up to 700 connections per second. This proliferation is later followed by a pruning phase, where unused connections are eliminated to enhance efficiency, adhering to the 'use it or lose it' principle.
This evolution persists throughout one's lifetime. Experiences can drive the creation of new connections, while unused connections might be discarded or downscaled during sleep. Remarkably, the brain's plasticity can even facilitate adaptation to adverse events, such as a stroke, which appears to reactivate certain critical developmental periods. There's even speculation that such critical periods could be pharmacologically reopened.
This dynamic nature of the brain sharply contrasts with the predominantly static characteristics of AI and ML systems. Traditional ML/AI models possess fixed architectures and a predetermined number of neurons, and they only undergo change during training phases when weights are adjusted. Analogously, some may contend that ML/AI systems use a form of pruning, where low-weight connections are eliminated (followed by retraining) to conserve memory and computational resources during inference. As discussed earlier, research efforts in ML/AI aim to enable models with adaptive capabilities inspired by brain plasticity such as continuous learning. Techniques like In-Context Learning (ICL) in Large Language Models (LLMs) offer additional context to counteract the model's static nature. Similarly, the Retrieval-Augmented Generation (RAG) in LLMs facilitates access to both longstanding and recent information, assisting models that may not have been trained with the latest data. Despite these advances, there remains substantial potential to enhance the dynamism of ML/AI systems, drawing inspiration from groundbreaking discoveries in neuroscience.
The Power of Surprise: The effect of surprise plays a critical role in the brain. Surprise heightens attention, a complex process involving various parts of the brain such as the PFC and the amygdala (especially when the surprise is tied to emotions and threats) as well as the dopaminergic and norepinephrine systems. This heightened attention aids tasks like memorization. Novelty, surprise, and increased attention can enhance long-term memorization, a process involving the amygdala and hippocampus. As mentioned earlier, the brain consistently predicts and adjusts. A surprising prediction error serves as a robust signal to modify our "model of the world", a process involving the dopaminergic pathway in the midbrain. Some studies indicate that surprise can boost neural plasticity, enabling the brain to adapt more rapidly to unexpected events. While AI has utilized similar mechanisms, particularly in predictive algorithms, the brain's strategies and processes still hold lessons for the advancement of AI.
Motivation and Reward: As discussed earlier RL is a critical AI subfield that will continue to be inspired by Neuroscience. Intriguingly, some studies suggest that the brain might employ a form of TD learning, wherein our dopaminergic system shapes learning and decision-making. There's evidence that dopamine neurons encode reward prediction errors. Unexpected rewards induce a dopamine surge, while anticipated rewards reduce dopamine levels. Experiments with animals have observed dopamine surges linked to anticipated rewards, aligning with the TD learning principle of updating predictions based on earlier states or stimuli. While asserting that TD learning wholly replicates the brain's reward systems would be an oversimplification, it illustrates another domain where neuroscience and AI can mutually enrich each other.
Conclusion
While AI and Neuroscience have evolved in parallel over the past 50 years, often at different paces and with limited connections, it now seems evident that the future depends on both disciplines learning from each other. AI has experienced a few 'winters' in the past, punctuated by significant breakthroughs, one of which was the emergence of Generative techniques now prevalent across various industries. Neuroscience has also evolved significantly over the past century. Still, the brain has managed to keep many of its secrets, standing out as the most powerful and energy-efficient device in the universe. Embracing a genuinely multidisciplinary approach with tight coupling between these two disciplines promises exciting discoveries and the development of technologies that can significantly benefit the world. This could mark the beginning of a new journey for science and technology.
Acknowledgment:
The list of people I would like to thank for their insights and collaboration since I began my journey with AI years ago is extensive and probably wouldn't fit in this document. Firstly, I'd like to express my gratitude to Cisco for providing me the opportunity to develop numerous AI products for the Internet. Additionally, I'm indebted to them for granting me over 650 patents in the fields of Networking and AI. My heartfelt appreciation also goes out to the incredibly talented engineers on my team, with whom I've been innovating for years. In the realm of AI, I have been inspired by a number of AI scientists and researchers such as Geoff Hinton, Yann LeCun, Fei-Fei Li, Andrej Karpathy, Demis Hassabis, Ian Goodfellow, Jeff Dean, Ilya Sutskever, Yoshua Bengio, and Max Tegmark. In my pursuit to deepen my understanding of Neuroscience, I've been profoundly inspired by numerous legends in the field. A few of these notable figures include Santiago Ramon y Cajal, Camillo Golgi, Hubel and Wiesel, Edvard and May-Britt Moser, John O’Keefe, Linda B. Buck, Marian C. Diamond, Jeff Lichtman, Robert Sapolsky, James McClelland, Fei Fei Li and many others. I've also had the privilege of interacting with many highly recognized and inspiring neuroscientists, such as Adeel Razi, Subutai Ahmad who kindly reviewed this paper, among others. I'd like to extend special thanks to the authors of the diagram in this document, though regrettably, I cannot personally thank some of them as I am unaware of their names.
Any and all opinions and views expressed throughout the content of this document are JP Vasseur’s own and shall not be deemed to reflect the views of any potential affiliates.