

Focusing on Relevant Metrics for AI Systems!
This short WP discusses the evaluation of AI/Machine Learning (ML) systems, emphasizing the importance of selecting appropriate performance metrics based on the system's task and context. It begins by describing simple ML use cases where the system's performance is synonymous with the efficacy of the underlying ML algorithms, for which well-specified metrics exist These metrics are straightforward and can be adjusted to meet business needs, such as reducing false positives. The discussion broadens to complex AI systems involving Large Language Models (LLMs), mentioning various benchmarks used to assess LLMs, such as the AI2 Reasoning Challenge, HellaSwag, and Multitask Multidomain Language Understanding (MMLU). These benchmarks test different aspects of LLM capabilities, from reasoning to mathematical problem-solving. The text emphasizes the need for designing specific metrics that reflect an AI system's performance for its intended task. This task-oriented approach is crucial for evaluating the efficacy of AI systems, alongside considering other performance indicators like processing cost and latency. In conclusion, the text stresses the importance of focusing on key, task-specific metrics to accurately evaluate an AI system's performance, highlighting that generic metrics for LLMs, while useful, may not always reflect the model's effectiveness in different contexts. This approach is vital for the successful deployment and optimization of AI projects.
AI/Machine Learning (ML) is usually viewed through the lens of an algorithm; in some cases, simple systems are designed for a concise task. Take, for example, the task of training a classifier such as a Support Vector Machines (SVM) or a Neural Nets to detect the presence of a specific malware. Although the task itself may not be straightforward, simple performance metrics exist to assess the efficacy of the system, such as precision or recall, to characterize both the system's and algorithm's performance. Moreover, these metrics (Recall, Precision, F1 score) are easily interpretable. Algorithms may even be tuned toward a specific metric according to business needs; for instance, it may be desirable to increase precision, even if recall is not optimal, should the priority be to avoid False Positives (FP). An example of this is Predictive Networks, as discussed in [https://jpvasseur.me/predictive-networks](https://jpvasseur.me/predictive-networks), where the task involves predicting Internet issues (Service Level Agreement Violations) and triggering proactive rerouting actions. Such actions may have undesirable effects if improperly triggered, thus necessitating high precision (a low number of FPs), although Recall could be small (as there is no such prediction in today's Internet). In other situations, False Negatives (FNs) are highly undesirable, thus making it imperative to increase Recall, which may come at the cost of less optimal Precision.
The system's performance is somewhat synonymous with the algorithm's performance.
Now consider the case of an Anomaly Detection (AD) system used to detect issues / anomalies, which people usually describe as the 'simple' task of learning a baseline and detecting deviation'. Which metric should be used in order to reflect the system efficacy ? The main challenge here is due to the lack of ground truth (not really the metric being used). Indeed, in contrast with the previous example where a sample belongs to a given class, an AD algorithm may be used to flag "statistical anomalies". For the sake of illustration, consider a AD algorithm trained to regress percentiles and raising events falling outside of a predicted range of values; a fixed percentage of events would be flagged as 'anomalous', which in production systems do not necessarily translate to anomalies (from an user standpoint). This highlights the potential challenge of statistical anomalies not matching user relevant anomalies. In such a case, the performance of the algorithm may become unspecified, as is the performance of the overall system. It is worth noting that the overall system's efficacy relies on several other variables, such as the training strategy, size, quality, and diversity of the dataset, to name a few (not just the algorithm itself).
Let's now explore the challenge of assessing efficacy of a complex AI system, such as Gen-AI, made of a myriad of components.
Consider the case of an engine used to perform network troubleshooting. Such a system similarly to many other LLM-based architectures may be composed of a several components:
- One or more Large Language Models (LLM) and/or Small Language Models (SML), potentially using a Mixture of Experts (MoE), with various training strategies (SFT, quantization, LoRA, etc.) and training sets (varying in size, diversity, and quality)
- Knowledge/Vector Database (potentially trained end-to-end with specific embeddings)
- RAG strategies
- Prompt Strategies (Chain/Tree of Thoughts, instructions, etc.), with different context sizes
- Access to API for real-time data access, each with its own data quality.
Clearly, the overall system performance (in this case, the task of troubleshooting a network) depends on a very large number of variables and parameters
Still, people often pay a great deal of attention to metrics related to the LLM itself (although critical, one of the many components of the system). For example, HuggingFace assesses open LLMs based on various benchmarks from the Eleuther framework in order to determine the overall ability of LLMs to reason, solve various tasks, and the LLMs' general knowledge across various fields. For the sake of illustration:
AI2 Reasoning Challenge (ARC): The AI2 Reasoning Challenge (ARC) is a benchmark metric designed to assess the reasoning capabilities of Large Language Models (LLMs). It consists of a set of grade-school level multiple-choice science questions, which are intended to test the model's ability to understand, reason, and apply scientific knowledge. The challenge is notable for its focus on complex questions that require more than simple retrieval of facts, aiming to evaluate the deep understanding and reasoning power of AI systems in a structured and quantifiable way.
HellaSwag: HellaSwag is a benchmark designed to test the common sense reasoning of Large Language Models (LLMs). It presents models with a set of incomplete scenarios from a diverse range of everyday topics, requiring the model to predict the most plausible continuation from a set of provided options. This challenge is particularly focused on assessing a model's ability to understand and predict human-like pragmatic inferences, pushing the boundaries of AI's understanding of context and real-world logic.
Multitask Multidomain Language Understanding (MMLU): The Multitask Multidomain Language Understanding (MMLU) metric is a comprehensive evaluation framework designed for Large Language Models (LLMs). It encompasses a wide array of subjects, including professional, scientific, and humanities disciplines, to test the model's understanding across diverse domains. MMLU aims to assess a model's ability to apply knowledge and reasoning skills to answer challenging questions, reflecting a more holistic measure of the model's understanding and versatility in multiple knowledge areas.
TruthfulQA: TruthfulQA is a benchmark designed to evaluate the truthfulness and factual accuracy of responses generated by Large Language Models (LLMs). It comprises a set of questions specifically crafted to probe areas where models might generate misleading, false, or biased answers. The goal of TruthfulQA is to assess a model's ability to discern and adhere to factual correctness over plausibility or popularity of information, thereby addressing the challenge of ensuring reliable and truthful output from AI language systems.
GSM8K: GSM8K, short for Grade School Math 8K, is a benchmark designed to assess the mathematical problem-solving abilities of Large Language Models (LLMs). This dataset consists of over 8,000 mathematics problems, typically found in grade school curricula, ranging from basic arithmetic to more complex multi-step problems. The GSM8K challenge tests a model's capacity to understand and solve mathematical questions, providing a quantitative measure of its computational and logical reasoning skills in the context of mathematics.
Winogrande: Winogrande is a large-scale dataset designed to measure the ability of Large Language Models (LLMs) to resolve ambiguous pronouns in sentences. This challenge involves sentence completion tasks where a model must choose the correct entity that a pronoun refers to, based on the sentence context. The Winogrande metric is notable for its focus on assessing a model's understanding of nuanced linguistic context and its capability to perform accurate pronoun resolution, a key aspect of natural language understanding.
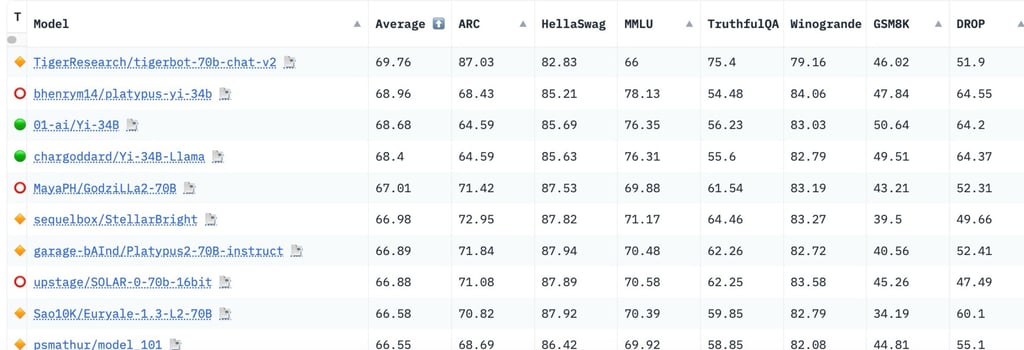
Note that they are several other metrics dedicated to multi-modal models:
MMMU: The Multitask Multidomain Language Understanding (MMLU) metric is an advanced evaluation framework designed to assess the efficacy of Large Language Models (LLMs). It encompasses a diverse range of topics spanning professional, scientific, and humanities disciplines, thereby challenging the model's understanding and adaptability across varied domains. MMLU aims to gauge a model's ability to apply knowledge and reasoning skills in answering complex questions, providing a comprehensive measure of its versatility and depth of understanding in multiple knowledge areas.
VQAv2: The Visual Question Answering v2.0 (VQAv2) metric is designed to evaluate the performance of Large Language Models (LLMs) in understanding and interpreting visual content. This metric involves presenting the model with an image accompanied by a related question, requiring the model to accurately interpret the visual information and provide a relevant answer. VQAv2 tests the model's ability to integrate visual and textual understanding, highlighting its proficiency in processing and synthesizing multimodal information.
TextVQA: TextVQA is a metric used to assess Large Language Models (LLMs) in the context of answering questions based on text present in images. This challenge requires the model to recognize and understand textual information within a given image and then use this understanding to answer questions related to the text. TextVQA evaluates the model's capabilities in both visual text recognition and natural language understanding, highlighting its effectiveness in processing and integrating multimodal data.
Summary text in italic was generated by a LLM.
Does that mean that those metrics are useless? Not at all. Each metric provides a useful overview of LLM performance for specific types of tasks, such as reasoning, solving math problems, or translation capabilities.
The real challenge, though, and the key to success when designing an AI system for some industrial applications, is to design a few metrics that will be indicative of the system's performance for the task at stake. This is easy to say but most of the time hard to achieve. First and foremost, it is imperative to consider a few metrics that are directly related to the task solved by the system. For example, in the case of network troubleshooting, one may design a binary outcome (success, failure) reflecting whether the system managed to troubleshoot (find the root cause). For some issues, the answer is well-defined, making the test quite straightforward (e.g. "What are the top-5 interfaces with the highest packet error rates on average for the past 5 days"). In other cases, the answer is not black or white, and there may be multiple root causes. This implies that the system designer must carefully develop these metrics, specifying a specific function and sometimes a specific algorithm used to evaluate the system outcome (success or failure) or a score. Such a metric is crucial especially with systems using such a metric to trigger self-optimization (loss-function used during training, ..). Spending time on Framework evaluation focussed on the system performance for the specific task at hand is absolutely fundamental.
Additionally, one may monitor other performance metrics of the system (which may or may not be used for optimizing the system), such as:
Processing cost
Latency (time to accomplish the task)
Required resources in terms of CPU, memory
Ability to generalize across multiple sub-tasks
In conclusion, it is essential to concentrate on the key metrics that define an AI system's performance in relation to the objectives of the use case, as this focus is critical for the success of the project. Generic metrics for Large Language Models (LLMs), even when they encompass a broad range of tasks to reflect a specific capability such as reasoning, are always interesting, but they may not be indicative of the performance of the model in a different context. Furthermore, the LLM is 'just' one of the many components of the overall system. Thus, it is imperative to build a Benchmark system centered on well-designed metrics reflecting the efficacy of the system for the task at hand, even though such a Framework may be time-consuming and sometimes require deep engineering.