

If You Are Planning to Build a Gen AI Product, Read This!
The paper contrasts traditional product development cycles with those of Machine Learning (ML) and Generative AI (Gen-AI) systems, highlighting the unique challenges each faces, such as the importance of data quality in ML and the need for specific success metrics and hyperparameter adjustments. It notes that Gen-AI, particularly through transformers and attention mechanisms, introduces complexity in development and evaluation, but also offers a lower barrier to entry and rapid innovation, despite challenges in determinism, transparency, and interpretability. While Gen-AI systems promise significant advancements and applicability, they require rigorous evaluation and a nuanced understanding of their development and deployment complexities.
As with any engineering project, the design phase is followed by the development cycle, which concludes with a qualitative assessment phase (testing) after which the project move to alpha, beta, and then general availability. In traditional development (e.g., implementing a new routing protocol), the specification serves as the starting point, with a clear definition of objectives, variables, algorithms, and finite state machines (FSM). Deep test cases would then be run to check protocol compliance, allowing some room for modifications during protocol implementation.
As Machine Learning (ML) began to emerge, product development started facing unusual challenges. First of all, developments were dependent on the quality of data used to train algorithms, especially with connectionist algorithms such as Neural Networks or Large Language Models. The quality (and diversity) of training data is critically important, highly influencing the overall system's efficacy—sometimes even more so than the algorithm itself. Then, another challenge arose: unlike "simpler" code development that uses a well-defined system (e.g., the FSM of a protocol), it became necessary to define metrics to reflect system efficacy. As discussed in [Focusing on Relevant Metrics for AI Systems!], some systems are tightly tied to the underlying ML algorithm, such as classification problems, for which well-defined metrics exist that are also easy to interpret, such as Recall, Precision, F1 scores. In contrast, other ML/AI systems require the development of system-level performance metrics due to their complexity and the myriad of components involved.
Development cycles of ML-based products can be summarized as follows:
- Use case specification along with success metrics,
- Data collection and cleansing for training and testing (involving data scientists and field experts),
- ML algorithms and systems specification (involving ML and system engineers),
- Unit and System testing,
- Alpha/Beta testing,
- General Availability (GA).
In contrast with "classic" product development cycles, ML development introduces new challenges, primarily related to the specification of success metrics and the adjustment of algorithm(s) and system parameters (also referred to as hyperparameters). Moreover, most intuitions frequently prove incorrect mostly for a number of reasons (algorithms trained on massive multi-dimensional data, large number of hyperparameters, ...), which require the use to be extra rigorous (and scientific) during development and test cycles.
ML/AI development cycle exhibits the following properties:
- A (fairly) high barrier to entry, requiring data scientists, ML, and system engineers, although the availability of ML/AI platforms (PyTorch, Scikit-Learn, Keras, TensorFlow) and, nowadays, ML/AI Model-as-a-Service, has somewhat mitigated this.
- A (fairly) deterministic process
- A (fairly) clear path from Proof of Concept (PoC) to General Availability (GA).
The article ['What really changed with Gen-AI compared to "classic" ML systems: a technical perspective'] discusses in detail how such systems differ from their 'classic' ML counterparts with regard to barriers to entry, reliability, interpretability, the number of dimensions (hyperparameters), training, and inference costs, among other aspects.
With the adoption of Gen-AI, the landscape is profoundly changing:
- Low barrier to entry: What previously took months and involved engineers of different profiles to develop ML systems, can now be achieved in a matter of days/weeks. This is thanks to the availability of APIs for accessing full systems, including prompting, knowledge databases, ML models, and MLOps for monitoring model performance and costs. Alternatively, one may decide to assemble systems using existing knowledge vector databases, various prompting approaches, and (fine-tuned) open-source models (e.g., LLaMA, Orca, Mistral, Falcon), although this approach may start requiring much deeper expertise.
- Using strong data models: Often, Gen-AI systems gain real-time access to a myriad of other systems, providing access to a sheer number of sources thanks to open APIs. However, a commonly overlooked issue is the quality of the data retrieved via such APIs and used to feed the system via prompting (n-shot leaning). Take, for example, the Networking (cross-domain) APIs used by a networking troubleshooting engine; not only could the API be underspecified, but a given concept may also have different meanings according to the context, inevitably leading to confusion for the LLM handling the task at hand. For instance, the notion of 'Virtual Private Network' (VPN) could translate to VLAN for switching, MPLS VPN, or even micro-segmentation using SGT in security concepts. Thus, it may be necessary to normalize data using a common data model and schemas to disambiguate the semantics of the data. Deep engineer work in this are may often prove to be far more efficient than tweaking the algorithm itself or the prompting strategy.
- Transparency and interpretability challenges, though not specific to Gen-AI, are significant; several ML algorithms, such as Neural Networks and Deep Neural Networks (DNNs), are considered "black-box" algorithms. Despite interesting research in areas like mechanistic interpretability, LLMs remain opaque, often requiring extensive trial-and-error and systematic large-scale testing for tuning, while still lacking interpretability and transparency.
- New challenges in performance evaluation and debugging: As discussed earlier, Gen-AI systems, such as Large Language Models (LLMs), are undoubtedly hard to evaluate and require in-house, use-case-specific metrics evaluated using deep performance evaluation platforms, which are often complex projects themselves. Debugging of such systems is also harder mostly because of the lack of interpretability of Gen-AI algorithm and the inter-dependency between components.
- Predictability challenges: While classic ML introduces new challenges in predicting deliverables, these pale in comparison to Gen-AI-based systems. For Gen-AI, it becomes extremely challenging to predict when a product will meet the required quality standards, especially those of enterprise-grade.
- Handling the Pace of Change: Thanks to open innovation, the pace of innovation in the area of Gen-AI has been unmatched. Technologies, algorithms, and architectural improvements are continuously emerging, each coming with their own performance evaluation, which is usually not easily transferable to the issue at stake. Although development cycles tend to shorten, they do require a freezing period during which solution testing and improvements take place, resisting the temptation to adopt the new kid on the block.
- Scientific rigor is essential in the context of Gen-AI because such developments require a rigorous methodology of evaluation. Although science and engineering have long been perceived as orthogonal and sometimes antagonistic domains, scientific rigor becomes a must-have.
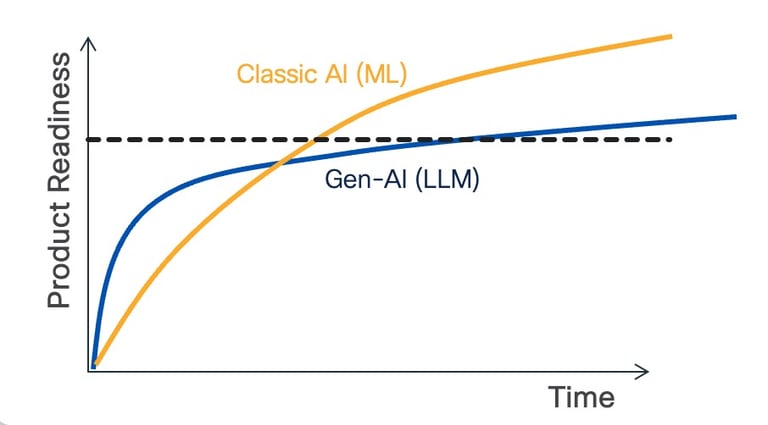
Conclusion
Without a doubt, the intricacy of Gen-AI systems stems from the myriad intertwined components involved, leading to a complex, often 'opaque' system that is hard to evaluate and robustify. The time to productization for Gen-AI systems is expected to have a different 'shape' compared to classic ML products. It starts 'easy,' allowing for a quick demonstration of the Proof of Concept, followed by a longer tail due to the extra complexity of such Gen-AI systems (e.g., the number of components and their interactions). Significant effort is required to determine when the product has reached a point where it can be safely deployed at scale, including the complexity of defining system-level efficacy metrics. This does not in any way diminish the strong attractiveness of Gen-AI and their unprecedented scope in terms of applicability and addressable use cases. However, it is crucial to be aware of the new types of challenges they present.